Una deficiente comprensión de conceptos estadísticos y la
enorme presión a que los investigadores de todas las áreas nos vemos
sometidos para publicar podría ser la causa de que la mayoría de los estudios científicos de áreas médicas, biológicas y de ciencias sociales lleguen a conclusiones erróneas con tal de publicar.Hace ya ocho años que el profesor John Ioannidis
publicó esta rotunda afirmación [1], para sorpresa de parte de la
comunidad científica y alivio de otros que por fin veían señalado al
elefante en la habitación. Pero los años pasan y es frustrante ver que
seguimos igual, tanto por parte de algunos autores (como el criticado aquí) como por periodistas que se “tragan” acríticamente cualquier cosa que comience por el manido “un estudio científico demuestra que…“.
 |
| (Créditos: XKCD-es) |
Por esto he decidido dedicar (otra) entrada a aclarar concepciones erróneas que pululan sobre la estadística, una de las herramientas más potentes que tenemos y sin embargo con peor fama entre el público general precisamente por su mal uso.
Sé que otros blogs ya han hablado del tema “causalidad vs. correlación”, así que le doy a dar un enfoque nuevo: explicar la verdadera relación que existe entre correlación, causalidad y grafos.
Chocolate y premios Nobel
“Los países con mayor consumo de chocolate tienen más premios Nobel, por lo que se recomienda su consumo para mejorar la inteligencia.”¿Te parece absurdo? A mí mucho. Pues esta asociación se llegó a publicar en una revista científica [2] y generó una ristra de titulares en todo tipo de medios, p.ej. aquí, aquí o aquí.
Los autores del estudio hipotetizaban que el efecto de los flavonoides del cacao sobre las capacidades cognitivas era tan importante que permitía la aparición de más premios Nobel allí donde más se consume. Rápidamente aparecieron críticas en las revistas científicas [3], donde se señalaba (entre otros puntos débiles del estudio) que muchos otros índices aparte del chocolate tienen una alta correlación con el número de premiados así que… ¿cuál es realmente la causa última?
Por ejemplo, entre los índices que correlaban salió el número de tiendas de IKEA en cada país:
 |
|
| Dos variables se dice que están correladas cuando el aumento (o disminución) de una provoca un cambio claro en la otra, lo que se suele traducir en que los datos representados como gráfica “parecen caer” sobre una línea en lugar de ser una “nube amorfa”. |
No creo que guardar los libros en armarios con nombres de pueblos noruegos te haga más listo. De hecho, puede que para llegar a ser un Nobel tenga más importancia el nivel socioeconómico de un país que la “inteligencia” de sus gentes.
Lo que se quería resaltar con esta anécdota de las tiendas IKEA es que, buscando, seguro se acabarán encontrando relaciones absurdas, así que sólo la correlación no justifica en absoluto la existencia de una relación de causa-efecto. De hecho, y aunque esto sea ya otro tema, la ausencia de correlación tampoco implica que no exista relación causa-efecto, ya que siempre quedará una probabilidad (pequeñísima) de haber obtenido una combinación de datos especialmente adversa.
Un error demasiado común
Antes de pasar a explicar el porqué aparecen estas correlaciones sin relación causal directa, quiero recopilar algunos “un estudio científico demuestra que…” para echar unas risas:- Lo del corazón partío les pasa factura a los solteros: “Los felizmente casados sobreviven más que los solteros tras un ‘by-pass’” (ElMundo)
- Lo mejor para dormir tranquilo es no enterarse de las noticias: “La sobreinformación es la causante del «síndrome de fatiga informativa»” (ABC)
- No es por no moverse del sofá, no, sino por mirar una pantalla: “Ver la televisión acorta la vida hasta en cinco años” (El Economista)
- Y este estudio fue ya de traca: “El tamaño del pene está relacionado con el crecimiento del PIB: Un investigador de la Universidad de Helsinki (Finlandia) ha llegado a la conclusión en un reciente estudio que el tamaño promedio del pene en un país, tiene directa relación con el crecimiento del Producto Interno Bruto (PIB) de cada nación.” (Noticias Terra)
 |
| Eje vertical: PIB. Eje horizontal: tamaño medio del miembro masculino. No, no es coña: alguien quiso imaginarse una correlación en esta nube de puntos…o quiso hacerse famoso. (Fuente) |
Grafos y causalidad
Vamos al meollo: ¿por qué aparece correlación entre variables? Hay varias posibilidades:
- (1) Causalidad directa: Una variable realmente se encuentra entre las causantes de la otra.
- (2) Causalidad indirecta: Existe un tercer hecho (o varios) que relaciona indirectamente los dos bajo estudio.
- (3) Casualidad con los datos: Si se seleccionan muy mal los datos, con sesgo intencionado o simplemente muy pocas muestras, puede “parecer” que hay correlación simplemente por azar. A veces también ocurre que simplemente existe correlación sin relación causal remota; p.ej. el precio del tomate en Cuenca puede subir a la par que el número de cines abiertos en China.
Los casos (1) son los típicos explorados en Física, donde existen
modelos bastante buenos de sistemas sencillos y cerrados donde se
controlan todas las variables de los experimentos. Los casos (3) suelen
ser fácilmente identificables con el sentido común, p.ej. el caso del
PIB y el tamaño del pene que menciono arriba.
Uno de los modelos gráficos más usados en estadística es el que representa las variables como nodos y las relaciones causales como arcos dirigidos (con “flechitas”). Este modelo se llama red Bayesiana y es un formalismo matemático extremadamente potente.Veamos un ejemplo clásico en este tema: las relaciones entre que haya llovido (LL), que la hierba esté húmeda (H) y que hayan funcionado los aspersores o rociadores para regar (R). Se tienen tres nodos y las relaciones son:
 |
| (Créditos) |
Cada flecha A -> B indica que A influye (es una causa) de B. Leamos la información que codifican los arcos del ejemplo:
- LL->R: Si llueve no se enciende el aspersor, ya que no hace falta.
- R->H: Si se ha regado, la hierba estará mojada.
- LL->H: Si llueve, la hierba estará mojada.
Correlación y distribuciones marginales
Por fin llegamos al quid de la cuestión: ¿qué pasa cuando estudiamos la correlación entre variables de un grafo?Esto es lo que normalmente se hace con los estudios médicos y de otro tipo: se escogen dos (o más) variables entre las que se hipotetiza una relación causal y se pone a prueba mediante técnicas estadísticas (e.g. test chi2, etc.). Ahora, si la realidad es que A implica B, el modelo real es:

y se debería encontrar correlación. Por tanto, la clave para poder asociar correlación con causalidad de manera rotunda es estar seguros de que la única causa posible de B es A… o que tiene más causas pero todas ellas son independientes de A. Algo bastante difícil de asegurar en cualquier modelo complejo como puede ser la salud de una persona donde intervienen tantos y tantos factores.
Veamos algo más interesante: qué ocurre cuando se ignoran hechos. Por ejemplo, imaginemos un evento C que es la causa de A y de B, como representa este grafo:

La distribución de probabilidad que modela perfectamente este sistema depende de tres variables, pero según la teoría de modelos gráficos podemos separarla (“factorizar” es el término matemático) en el producto de las funciones que modelan cada relación causal por separado:
¿Qué problema tiene esto? Pues que si estudiamos solamente A y B, olvidándonos de C, realmente se trabaja con la función:
donde se dice que C ha sido “marginalizado“, y toda la información de sus arcos pasan a crear un nuevo “arco” entre A y B… ¡Aunque inicialmente no existía relación causal alguna entre ellas!
En resumen: si se estudian dos variables dejando fuera causas comunes, se detectará una correlación entre ellas aunque no exista relación causal directa alguna. Este es el mayor peligro en cualquier estudio científico.
Curiosamente este efecto depende del sentido de las flechas: si ahora estudiamos solamente las variables A y B dejando fuera una C que es efecto de ambas, no detectaremos correlación entre A y B. Si reflexionas un momento sobre qué significan las flechas entenderás por qué esto es así de manera intuitiva.
Una regla general para saber si el ignorar un nodo C introduce correlación entre A y B es esta: si los caminos desde A a B se encuentran en una configuración “flecha-flecha” (como en este último dibujo), no aparece correlación, y sí aparece en cualquier otro caso.
Un ejemplo práctico: delincuencia y boy scouts
Quería terminar con un ejemplo numérico para aclarar los conceptos a quien nunca antes de hoy hubiese oído hablar de probabilidades marginales y cia. Lo he sacado de este excelente curso de la PennState University (EEUU).Tenemos los siguientes datos sobre 800 chicos a los que se clasifica por nivel socioeconómico (S), si son o no boy-scouts (B) y si tienen o no antecedentes delictivos (D):

¿Qué pasa si estudiamos la hipotética relación entre ser boy-scout y delinquir? Pues que tendríamos que “ignorar” (marginalizar) el nivel socioeconómico, sumando los datos sobre los distintos niveles (aquí un ejemplo del proceso) y llegando a:

Estos números, sometidos a tests estadístico gritan un: sí, existe correlación (negativa) entre ser boy-scout y delinquir. Luego: ¿los boy-scout son mejores personas? No tan rápido…
¿Y si el modelo subyacente a los datos fuese que el nivel socioeconómico fuese la causa de ambos, ser boy-scout y delinquir, sin que exista relación directa alguna entre estas últimas?
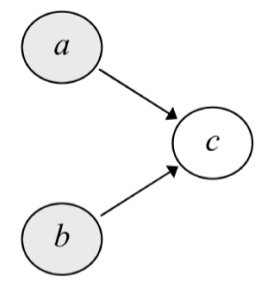
|
||
| Posible modelo causal alternativo: c: Nivel socioeconómico, a: ser boy-scout, b: delinquir. |
Poner a prueba este modelo es sencillo: se puede determinar si existe relación causal directa entre “a” y “b” en el grafo del dibujo poniendo a prueba la correlación de la distribución condicional de éstas para cada valor dado de “c”:
Y hacer tres pruebas de correlación entre ser boy-scout y delinquir para cada trozo de 2×2 de los datos, uno por cada nivel socioeconómico (low, medium, high).
Estas pruebas dan un resultado de correlación nula (la hipótesis nula arroja χ2=0.16), luego la apresurada hipótesis de que ser boy-scout te hace menos propenso a delinquir era errónea: el detonante real es el nivel socioeconómico, que a su vez condiciona que un chico se pueda permitir hacerse boy-scout o no.
Aunque el artículo me ha quedado “algo” denso y largo, ¡espero que lo hayas disfrutado! Puedes leer más en los enlaces que dejo abajo.
Referencias:
- [1] Ioannidis, J. P. (2005). Why most published research findings are false. PLoS medicine, 2(8), e124. (Paper)
- [2] Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367(16), 1562-1564. (PDF)
- [3] Maurage, P., Heeren, A., & Pesenti, M. (2013). Does Chocolate Consumption Really Boost Nobel AwardChances? The Peril of Over-Interpreting Correlations in Health Studies. The Journal of nutrition, 143(6), 931-933. (PDF)
- [4] https://onlinecourses.science.psu.edu/stat504/node/112
- [5] Un capítulo gratuito sobre graphical models: http://research.microsoft.com/en-us/um/people/cmbishop/prml/Bishop-PRML-sample.pdf