
La fórmula de arriba no es una cualquiera, es una de las más curiosas en matemáticas. Su representación en un gráfico es, básicamente, la propia fórmula. Se la conoce como la fórmula autorreferente de Tupper y su explicación es un genial ejercicio numérico que te hará amar (un poco más) las matemáticas.
Primero partamos de la fórmula en sí mismo. Es esta:

Si representáramos esta ecuación en un eje de X e Y, de forma que las coordenadas de X estuvieran entre 0 y 106, y las de Y estuvieran entre K y K+17, siendo K igual a este número enorme:
960939379918958884971672962127852754715004339660129306651505519271702802395266424689642842174350718121267153782770623355993237280874144307891325963941337723487857735749823926629715517173716995165232890538221612403238855866184013235585136048828693337902491454229288667081096184496091705183454067827731551705405381627380967602565625016981482083418783163849115590225610003652351370343874461848378737238198224849863465033159410054974700593138339226497249461751545728366702369745461014655997933798537483143786841806593422227898388722980000748404719
El resultado del dibujo en el gráfico sería la propia fórmula pixelada, es decir, esto:

¿Cómo es posible? Básicamente, las reglas de las coordenadas mencionadas, 0106×17, en el que cada celda podría ser un bit de información, o lo que es lo mismo, 106 x 17 = 1802 bits.
A su vez, el número K contiene 543 cifras que permiten codificar 1810 bits de información binaria. Es decir, el número K es justo el que codifica y dibuja en el gráfico la fórmula, con un 0 asignado a la celda libre y un 1 asignado a la celda coloreada. Esto, automatizado por un programa informático como el que creó Tupper, dibujaría al instante la propia fórmula con el número K mencionado. Por eso se le llama "auto-referente".
Como explica Matt Parker en el vídeo debajo, se podría comprobar de forma manual. Si partes del dibujo de la fórmula y anotas su número binario, asignando un 1 cuando la casilla está coloreada y un 0 cuando no, divides ese número binario final entre 10 y lo multiplicas por 17, obtendrías el número K inicial.

Lo curioso de todo esto es que, solo variando el número K, puedes obtener un dibujo diferente cada vez. Lo que quieras. Por ejemplo, como explican aquí, si K (o N, da igual cómo lo llames) fuera este número:
6064344935827571835614778444061589919313891311
Obtendrías este dibujo final:

Si K fuera este otro número:
11446143048577322873420746886032253602081036176820637725351572728824205319356548595443573778191478330600315648025516347418384227839098139252614970555108049338384907856705947495396329029490965408180552069582726103040
Obtendríamos esta representación:

Puedes echar un vistazo al vídeo completo de Matt Parker debajo. Está en inglés, pero paso a paso muy clarito explicado:
Fuente:

=\sum_{n=1}^{\infty}\frac{1}{n^2}=\frac{1}{1^2} +\frac{1}{2^2}+\frac{1}{3^2}+\cdots,")
=\sum_{n=1}^{\infty}\frac{1}{n^2}=\frac{\pi^2}{6}") .
.=\sum_{n=1}^{\infty}\frac{1}{n^4}=\frac{\pi^4}{90}") ,
,") (en función de los llamados números de Bernoulli). ¿Este resultado fue
inventado o descubierto por Euler? ¿Tiene sentido que Euler patente la
“invención” del método que le llevó a este resultado?
(en función de los llamados números de Bernoulli). ¿Este resultado fue
inventado o descubierto por Euler? ¿Tiene sentido que Euler patente la
“invención” del método que le llevó a este resultado?") ?
El método de Euler no funciona. ¿Tiene sentido patentar un método para
calcular estos valores de la función zeta? ¿Se inventa o se descubre un
método para calcularlos? Mi experiencia personal es más próxima a que se
descubre un método explorando las propiedades de estos objetos
matemáticos. Sin embargo, reconozco que el esfuerzo a veces es tan
grande que a uno le gustaría patentar la herramienta “inventada” en el
proceso.
?
El método de Euler no funciona. ¿Tiene sentido patentar un método para
calcular estos valores de la función zeta? ¿Se inventa o se descubre un
método para calcularlos? Mi experiencia personal es más próxima a que se
descubre un método explorando las propiedades de estos objetos
matemáticos. Sin embargo, reconozco que el esfuerzo a veces es tan
grande que a uno le gustaría patentar la herramienta “inventada” en el
proceso.=\sum_{n=1}^{\infty}\frac{1}{n^z}=\prod_{i=1}^{\infty}\left(1-\frac{1}{p_i^z}\right)^{-1},")
 es el número primo
es el número primo  -ésimo (
-ésimo ( , etc.). Se puede demostrar fácilmente que si la variable
, etc.). Se puede demostrar fácilmente que si la variable  es un número complejo
es un número complejo +\mbox{i}\,\mbox{Im}(z)") , con
, con  , estas series convergen para
, estas series convergen para >1") (de hecho, es muy fácil demostrar que estas series divergen para
(de hecho, es muy fácil demostrar que estas series divergen para  ).
).") de variable compleja para
de variable compleja para <1") ?
¿Piensas que se descubre esta extensión o que se inventa un método para
calcularla? Ya te digo, yo prefiero decir que se descubre la extensión y
que se descubre la herramienta para calcularla.
?
¿Piensas que se descubre esta extensión o que se inventa un método para
calcularla? Ya te digo, yo prefiero decir que se descubre la extensión y
que se descubre la herramienta para calcularla.") de Dirichlet corresponde a la versión alternada de la serie, es decir,
de Dirichlet corresponde a la versión alternada de la serie, es decir,=\sum_{n=1}^{\infty}\frac{(-1)^{n-1}}{n^z},")
>0") y que permite escribir
y que permite escribir=\frac{1}{1-2^{1-z}}\,\eta(z),")
=\Gamma(1-z)\,{\cal J}(z),")
=\int_{0}^{\infty}u^{z-1}e^{-u}\,du,")
=\frac{1}{2\pi\mbox{i}}\int_{\cal{C}}\frac{u^{z}}{e^{-u} - 1}\frac{du}{u},")
 adecuado).
adecuado).=\chi(1-z),\qquad\chi(z)\equiv\pi^{-z/2}\,\Gamma(z/2)\zeta(z),")
 = 0")
 para
para  en la ecuación funcional). Además, la función
en la ecuación funcional). Además, la función  > 1") , luego los ceros triviales son los únicos para
, luego los ceros triviales son los únicos para <0") .
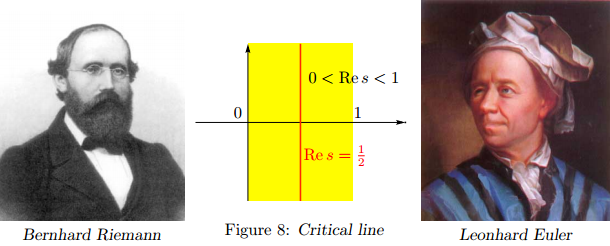
.\le 1") ? Todos estos ceros son simétricos respecto a la línea crítica
? Todos estos ceros son simétricos respecto a la línea crítica  = 1/2") . Más aún, si
. Más aún, si  es un cero complejo, también lo son
es un cero complejo, también lo son  ,
,  y
y  . La excepción son los ceros en la línea crítica
. La excepción son los ceros en la línea crítica